
Which AI? Deep Learning - Machine Learning - Representation Learning
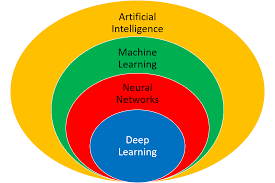 Deep Learning (DL) is a type of machine learning (ML), which is a subset of artificial intelligence (AI). Machine learning is about computers being able to think and act with less human intervention; deep learning is about computers learning to think using structures modeled on the human brain.
Deep Learning (DL) is a type of machine learning (ML), which is a subset of artificial intelligence (AI). Machine learning is about computers being able to think and act with less human intervention; deep learning is about computers learning to think using structures modeled on the human brain.
Keras is a high-level, deep learning API developed by Google for implementing neural networks. A neural network is a series of algorithms that endeavors to recognize underlying relationships in a set of data through a process that mimics the way the human brain operates. In this sense, neural networks refer to systems of neurons, either organic or artificial in nature.
TensorFlow is an open-sourced end-to-end platform, a library for multiple machine learning tasks, while Keras is a high-level neural network library that runs on top of TensorFlow.
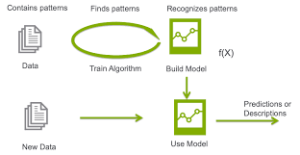 Machine Learning (ML) is a type of artificial intelligence (AI) is to use computers to learn information, without being explicitly instructed to do so. Most often, this involves using a set of historical outcomes, to make predictions about future outcomes.
Machine Learning (ML) is a type of artificial intelligence (AI) is to use computers to learn information, without being explicitly instructed to do so. Most often, this involves using a set of historical outcomes, to make predictions about future outcomes.
Common algorithms you will find within Supervised Learning include:
Regression: where you predict a real value output or amount of something, based on past inputs; e.g. predicting house prices, predicting purchase amounts (an example of a linear regression is shown in the diagram above)
Classification: where you predict discrete value outputs of something (often notated as 0 or 1), based on past inputs; e.g. predicting whether a customer will churn vs. not churn, predicting whether a student will pass vs. fail a class
Supervised Learning refers to the subset of Machine Learning where you generate models to predict an output variable based on historical examples of that output variable.
Unsupervised Learning is the subset of Machine Learning that helps with such a case. Given a dataset without a defined output variable, Unsupervised Learning algorithms will help find structure or patterns in the underlying data.
 Representation learning (RL) is a class of machine learning (ML), which is a subset of artificial intelligence (AI). Representation learning is a set of techniques that allows a system to automatically discover the representations needed for feature detection or classification from raw data.
Representation learning (RL) is a class of machine learning (ML), which is a subset of artificial intelligence (AI). Representation learning is a set of techniques that allows a system to automatically discover the representations needed for feature detection or classification from raw data.
How does Canviz Help?
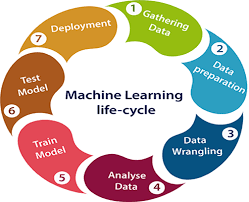 Collecting Data:
Collecting Data:
The quality of the data that you feed to the machine will determine how accurate your model is. Make sure you use data from a reliable source, as it will directly affect the outcome of your model. Data types can be DB/text datasets, images, voice, or video depending on your ML needs.
Preparing the Data:
Putting together all the data you have and randomizing it. Cleaning the data to remove unwanted data, missing values, rows, and columns, duplicate values, data type conversion, etc. Splitting the cleaned data into two sets – a training set and a testing set. The training set is the set your model learns from. A testing set is used to check the accuracy of your model after training.
Choosing a Model:
It is important to choose a model which is relevant to the task at hand. Over the years, scientists and engineers developed various models suited for different tasks like speech recognition, image recognition, prediction, etc.
Training the Model:
Training is the most important step in machine learning. You pass the prepared data to your machine learning model to find patterns and make predictions. It results in the model learning from the data so that it can accomplish the task set. Over time, with training, the model gets better at predicting.
 Evaluating the Model:
Evaluating the Model:
After training your model, you have to check to see how it’s performing. This is done by testing the performance of the model on previously unseen data. When used on testing data, you get an accurate measure of how your model will perform and its speed.
Parameter Tuning:
Once you have created and evaluated your model, see if its accuracy can be improved in any way. This is done by tuning the parameters present in your model. Parameters are the variables in the model that the programmer generally decides.
Making Predictions:
Some ML projects can be used to make future predictions based on dataset trends. There are a few approaches that can be used for making predictions, for Machine Learning Decision trees are powerful form of multiple variable analysis or Regression (linear and logistic) and Deep Learning Neural networks Convolutional Neural Networks (CNN) are the go-to method for any type of prediction problem.
Canviz AI Technology
Canviz has adopted some of the best AI technology available:
 PyTorch is based on the popular Torch library. It is designed to provide good flexibility and high speeds for deep neural network implementation. PyTorch is different from other deep learning frameworks in that it uses dynamic computation graphs.
PyTorch is based on the popular Torch library. It is designed to provide good flexibility and high speeds for deep neural network implementation. PyTorch is different from other deep learning frameworks in that it uses dynamic computation graphs.
 Keras is a powerful neural network deep learning library that runs on top of other open-source machine learning libraries such as TensorFlow and is also open-source itself. To develop deep learning models, Keras adopts a minimal structure in Python that makes it easier to learn and quick to write.
Keras is a powerful neural network deep learning library that runs on top of other open-source machine learning libraries such as TensorFlow and is also open-source itself. To develop deep learning models, Keras adopts a minimal structure in Python that makes it easier to learn and quick to write.
 Anaconda is a platform for Python/R programming languages. It provides more than 1500 Python/R data science packages which are suitable for developing machine learning and deep learning models.
Anaconda is a platform for Python/R programming languages. It provides more than 1500 Python/R data science packages which are suitable for developing machine learning and deep learning models.
Related Articles
-

How We Use AI to Build Software Faster, Cheaper, and More Secure
At our company, AI is deeply embedded into our development workflow. We use it to move faster, reduce costs, and improve security and code quality, while still keeping humans firmly in control of every decision that matters.
-
Elevate your marketing efforts with SharePoint + AI
Are you a marketer navigating the world of SharePoint but haven’t ventured into the realm of AI yet? Feeling a bit overwhelmed by the AI discussions and sensing the urgency to embark on the AI journey? Let’s discuss how SharePoint can kick-start the AI journey.
-

Enhancing Development Productivity with AI: A Personal Journey
In my 18-year journey as a software developer, I’ve embraced various tools to enhance productivity and creativity. Recently, I ventured into a domain where my experience was limited – working with complex Excel formulas. This post narrates how AI, particularly ChatGPT, played a pivotal role in this new challenge.
-

Azure Open AI – Microsoft & OpenAI Partnership – Merge Azure & ChatGPT/AI Technology
“Azure Open AI” is a new AI service created by a strategic partnership between Microsoft Azure and OpenAI (creator of ChatGPT) that will launch later in 2023.
Contact us at the Canviz office nearest to you or submit a business inquiry online.
“I confidently endorse the Canviz team and Tim for their exceptional work in developing our immigration management platform. Their ability to translate complex legal workflows into a streamlined, intuitive system has been invaluable. Throughout the process, they demonstrated strong technical expertise, responsiveness, and a clear commitment to getting the details right. The end result has significantly improved our operational efficiency and client experience. They delivered exactly what we needed with professionalism and precision.”
