- April 26, 2018
- Posted by: Alec McDaniel
- Categories: Hands-on Labs, News

What is Serverless?
Serverless computing is an exciting and promising cloud execution model in which the cloud provider dynamically manages the allocation of machine resources for you. It is only “serverless” in the sense that it takes away the pain of having to manage the infrastructure yourself, but of course there are still servers involved.
This allows for a pay-as-you-go model. If the cloud provider detects that your serverless services need more resources because you suddenly get more traffic, it will automatically scale up. Then when traffic becomes less, it will automatically scale down.
Since you don’t have to worry about infrastructure, your time-to-market can be significantly decreased. You as a developer can focus on writing business logic and connecting to other serverless components and quickly deploy a service in the cloud.
Evolution
The evolution of client-server applications has come a long way.
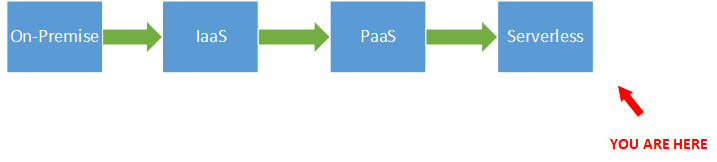
On-Premise
In the old days when we deployed our applications on-premise on physical machines, there was a lot to worry about: hardware, OS, security, backup, clustering, monitoring, patching, scaling, etc. etc.
IaaS
Then came along the cloud which offered VMs (Virtual Machines) as an IaaS (Infrastructure-as-a-Service) so you no longer had to worry about hardware, although you still had to worry about patching, monitoring, etc.
PaaS
This is when PaaS came along, which allowed you just deploy your code in the cloud environment, that would then take care of the rest, except scaling. In PaaS you are basically still responsible for assigning the resources and scaling and up and down based on your needs.
Serverless
Serverless goes all the way, and delivers true abstraction from the infrastructure concerns. This allows you to truly focus on the business problem you are trying to solve. And since it is pay-as-you-go you are not paying for idling infrastructure, which makes the serverless approach more cost-effective as well.
Big Data Processing
Microsoft Azure offers different components that allows you to write sophisticated applications in a serverless environment. Canviz has written several hands-on labs for Microsoft helping the reader develop serverless solutions for Big Data Processing. These include the use of Microsoft Azure components such as:
The core of serverless computing. Allows you to write code in many different languages immediately and publish it as a publicly accessible API.
Massively scalable object storage for unstructured data, also called blobs, such as binaries, images, office documents, text files, etc.
Allows collection and processing of millions of events per second in real-time.
Globally distributed, scalable storage facility for structured data.
To run massively parallel real-time analytics on multiple IoT or non-IoT streams of data using a simple SQL like language.
For when you need the sky to be the limit. Azure Data Lake Storage provides an enterprise-grade hyper-scale repository for big data analytical workloads. It supports HDFS, a distributed file system developed by Hadoop that allows very high bandwidth and high availability for distributed file storage.
Hands-on Labs

The hands-on labs for creating serverless data processing solutions includes all of the Azure components mentioned above. You can get it here.
It consists of 5 modules, starting with a simple file processing implementation up to a fully real-time stream processing and data archiving implementation.
- File Processing
In this module we will guide the reader through the steps to deploy a Azure Blob Storage triggered Azure Function that processing an incoming JSON file and stores the contents in Cosmos DB (a noSQL document database)
- Data Streaming
This module describes how to implement an IoT use case by simulating large amounts of incoming data from sensors in taxis to be processed and consumed in real-time by another application.
- Streaming Aggregation
Then, the application from the previous module is extended to aggregate the sensor data in real-time using Azure Stream Analytics
- Stream Processing
In this module, the aggregated taxi sensor data from the previous module is stored in Cosmos DB using an Azure Function implementation.
- Data Archiving
And finally, an Azure Date Lake Store is added to the mix to run analysis jobs against the raw data collected during the previous steps.
Big Data in your organization
We hope that these labs show the real power of serverless computing for processing large amounts of quickly changing data. Big data is everywhere and all the big cloud providers offer solutions that can help you implement serverless scenarios for big data processing. Reach out to us if you like us to help you out with implementing serverless or Big Data solutions in any one of them.
Cheers,
Manfred