- April 25, 2018
- Posted by: Alec McDaniel
- Category: News

MapReduce is a programming model that allows processing and generating big data sets with a parallel, distributed algorithm on a cluster. It allows for massive scalability across hundreds to thousands of servers in a cluster.
This all sounds like a very complex algorithm, but in fact it is just a complicated way of saying we are cutting up the workload in smaller parts, and the concept of a MapReduce task is actually easy to understand.
It basically consists of two parts: the mapping part and the reducing part, hence the name MapReduce.
The Map task takes input data and processes it to create key-value pairs. The Reduce task takes those key-value pairs and combines or aggregates them to produce the final result.
In other words, a MapReduce implementation consists of a:
- Map() function that performs filtering and sorting, and a
- Reduce() function that performs a summary operation on the output of the Map() function
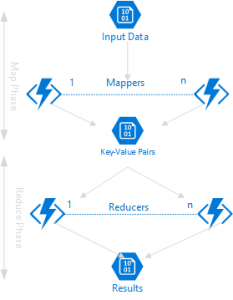
The Roman Census Approach
A great example of a MapReduce job is the Roman Census Approach. When the Romans decided they wanted to tax everyone in the Roman empire, they needed to count the total number of people in the Roman empire. Instead of centralizing this huge effort they assigned census takers to each city, and each of the census takers was responsible to count the number of people in the city. This corresponds to the Map task. Then, the result of all of the census takers was combined to come up with the total number of people in the whole Roman empire. This corresponds to the Reduce task.
Since Big Data is (still) very hot at this moment and MapReduce is at the heart of distributed computing, Microsoft Azure created a hands-on lab around the concept of MapReduce in combination with their serveless offerings to make it easy for developers to implement a MapReduce job.
Durable Functions
Microsoft recently released a preview version of their extension to Azure Functions called Durable Functions. The great benefit of these new Durable Functions is that you can write stateful functions in a serverless environment. Basically taking away one of the downsides of a serverless environment, the lack of out-of-the-box statefulness. In other words, Durable Functions make sure every consecutive request to a Durable Function picks up where it left off.
Durable Functions manages state across checkpoints and restarts for you, so you do not have to worry about having to implement your own way of keeping state.
This is a great feature if you want to process a workflow in parallel, such as MapReduce. Especially if you combine this with calling functions asynchronously, as not all of the tasks in a MapReduce job will complete at the same time, but you are going to need all the output before you can aggregate the intermediate results. This is where the Fan-out/fan-in pattern comes in.
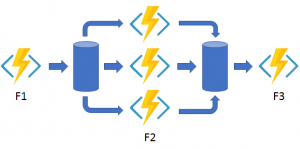
The Fan-out/Fan-in pattern will distribute the work across multiple instances of a function and then wait for all the results to complete before aggregating the results and proceed to the next step.
Big Data and Distributed Computing
Canviz is proud to have developed a lab around MapReduce and Azure Functions for the Microsoft Azure team.
Be sure to check it out and if your organization needs expertise implementing Big Data solutions, please to contact our team!
Cheers,
Manfred
The lab is no longer available? Any direction you can give? Thanks!
Hi Daniel. Thanks for your feedback. This article was published in anticipation of Microsoft publishing it soon after, but it seems we are still waiting for that. We will inquire with Microsoft. Please check back soon 🙂 Thanks, Manfred